- Published on
Từ LoRA đến LongLoRA: Nhẹ hơn, dài hơn và sướng hơn - Phần 1
- Authors

💡 Hilu mọi người, xin lỗi vì 2 tuần vừa rồi mình sống chết với deadline và thi cuối kì nên hôm nay mình mới quay trở lại với blog này. Hôm nay, mình sẽ giới thiệu với mọi người các kĩ thuật thông dụng để fine-tuning là LoRA, QLoRA và LongLoRA.
Chúng ta đều biết fine-tuning là một phương pháp của transfer learning, sử dụng weight của một pre-trained model để train với một bộ data mới, phù hợp với mục đích của người dùng và số lượng dataset thường nhỏ hơn khi pre-train. Việc làm này giúp tăng độ chính xác của model so với việc train trực tiếp với bộ dataset nhỏ của chúng ta. Thông thường, khi thực hiện fine-tuning, ta sẽ phải train toàn bộ hoặc một số layers của model, và cũng phải lưu lại toàn bộ các tham số của model hoặc một số layers của model được fine-tune luôn. Tức là với 10 downstream tasks, ta sẽ phải train toàn bộ model 10 lần, xong lại lưu lại weight của cả 10 models. Đối với những model nhỏ thì điều này không phải là một vấn đề lớn, tuy nhiên, trong cái kỉ nguyên mà người người nhà nhà sử dụng các model cực nặng, từ vài trăm triệu đến vài tỉ tham số thì việc train toàn bộ model, và lưu toàn bộ model là một vấn đề cực kì khó khăn với những người bị giới hạn về mặt phần cứng.
LoRA là gì?
Vì độ lớn của LLM đang tăng lên một cách chưa từng có nên chúng ta sẽ cố gắng không đề cập đến các tham số đã được huấn luyện mà sẽ thêm các layer vào LLM hoặc thêm giá trị vào các tham số. Các layer được thêm vào thường được gọi là “adapters” và kỹ thuật fine-tuning được gọi là “adapter-tuning”. Nó liên quan đến việc thêm các mô-đun adapter nhỏ vào mô hình được huấn luyện trước và chỉ huấn luyện các tham số trong mô-đun adapter.
Tuy nhiên, người ta phát hiện ra rằng các layer bổ sung gây ra độ trễ trong quá trình dự đoán, được gọi là Độ trễ Inference. Sẽ không dễ chịu nếu bạn phải đợi hơn 20 giây để LLM đưa ra câu trả lời. Sự cố này dường như không thể tránh khỏi vì các adapter layer được thêm tuần tự vào LLM, chúng phải được xử lý tuần tự và không có cách nào để xử lý song song. Bạn có thể sẽ thắc mắc tại sao không sử dụng batching để chia dữ liệu nhằm đạt tốc độ nhanh hơn. Ý kiến đó hay đấy. Nhưng trong quá trình sử dụng hoặc suy luận theo thời gian thực, người dùng thường nhập lần lượt từng prompt hoặc câu hỏi, do đó batch size là 1 và không có nhiều dữ liệu được batching.
LoRA (Low-Rank Adaptation of Large Language Models) không thêm layer mà thêm giá trị vào tham số. Giải pháp này sẽ không gây ra độ trễ inference. Ta sẽ sớm đi sâu vào kiến trúc của LoRA, nhưng tại thời điểm này, tất cả những gì bạn cần nhớ là: có các chiến lược fine-tuning khác nhau và chiến lược adapt-tuning có thể gây ra độ trễ inference. Bây giờ chúng ta đã biết adaptation có nghĩa là fine-tuning dữ liệu và tác vụ miền. Nó không được gọi là adapter vì nó không thêm adapter. Nó được gọi là adaption để mô tả quá trình thích ứng của nó.
Định nghĩa rank trong low-rank
Định nghĩa về rank của ma trận là số cột độc lập tuyến tính tối đa của ma trận. Dưới đây, chúng ta thể hiện hiển thị ma trận 2x3 và ma trận chuyển vị của nó với chiều 3x2. Lưu ý rằng hai hàng của ma trận hoàn toàn đối nhau. Chúng không độc lập tuyến tính. Hàng độc lập tuyến tính duy nhất là hàng đầu tiên. Vì vậy, cấp của V là 1. Tương tự như vậy, cấp chuyển vị của nó cũng là 1.
Các hàng hoặc cột bổ sung không có độc lập tuyến tính và có thể được xây dựng lại bởi các hàng hoặc cột khác. Với thuộc tính này, mặc dù ma trận có thể rất lớn nhưng thông tin thực sự của nó chỉ nằm trên các hàng hoặc cột độc lập.
Quá trình fine-tuning
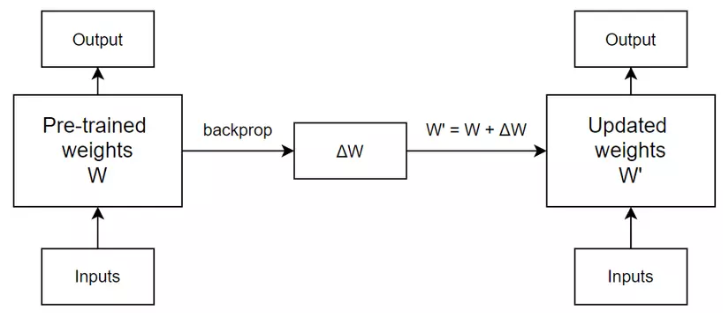
Pre-trained weights của model sẽ biến thành updated weights dựa trên giá trị weight cần thay đổi thu được từ quá trình back propagation. Và ở iteration tiếp theo, lại được update với một khác.
Quá trình forward sau mỗi iteration như sau:
- Iteration 0:
- Iteration 1:
- Iteration 2:
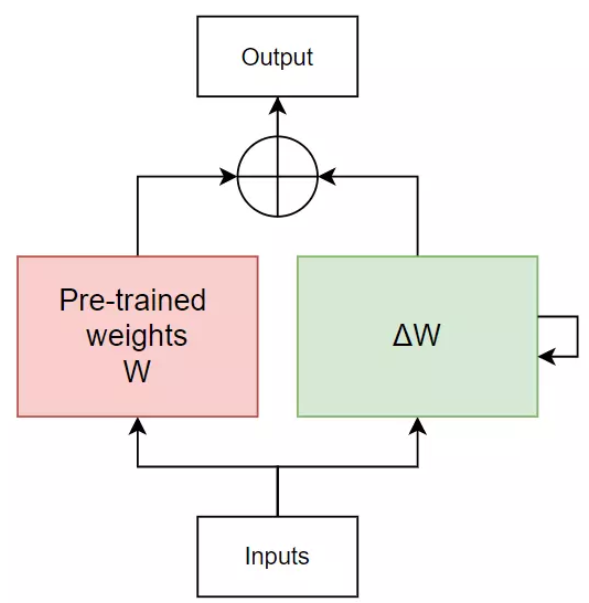
Mục tiêu của LoRA
Mục đích của LoRA là tìm cách biểu diễn ma trận $\Delta W$ thành một dạng biểu diễn nhẹ hơn. Năm 2020, có một paper nói rằng những mô hình ngôn ngữ pre-trained có intrinsic dimension (hay intrinsic rank) cực kì thấp, tức là, model này có thể được biểu diễn sử dụng số chiều ít hơn rất nhiều so với số chiều gốc của model, mà vẫn giữ được performance khi đem đi fine-tune.
Tận dụng ý tưởng này, nhóm tác giả của LoRA cũng cho rằng, cũng có thể được biểu diễn với số chiều ít hơn rất nhiều số chiều gốc của . LoRA chọn sử dụng Matrix decomposition để biểu diễn ma trận bằng tích của các ma trận con với độ nặng tính toán thấp hơn việc tính trên ma trận gốc. Có rất nhiều phương pháp Matrix decomposition (LU decomposition, Singular Value Decomposition, ...), và LoRA chọn sử dụng phương pháp Neural Network.
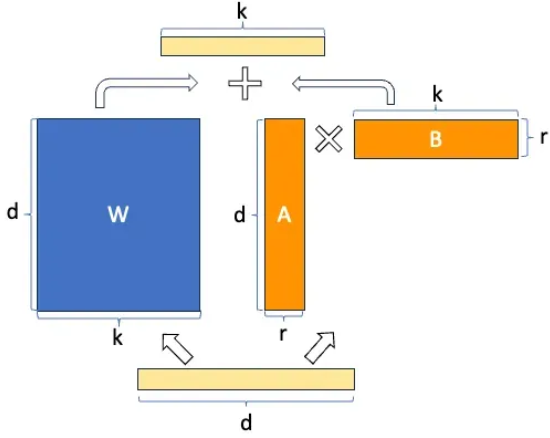
LoRA phân rã thành 2 ma trận con và với rank thấp hơn rất nhiều so với ma trận ban đầu. Cụ thể, với và số rank . Lúc này, output của layer đó sẽ trở thành
Ma trận A được khởi tạo theo Gaussian initialization, còn B thì được khởi tạo là ma trận 0, nên có giá trị bằng 0 khi bắt đầu training. Quá trình training sẽ tối ưu đê tính được 2 ma trận cần tìm.
Vậy tại sao việc phân tách này lại làm khối lượng tính toán nhẹ đi? Giả sử ta chọn . Khi đó, ta có số phần tử của ma trận là , còn số phân tử sau phân rã là , tức là khối lượng được giảm đi 12.5 lần.
Để có thể phân tách được một layer Linear, LoRA thêm vào Linear layer đó 2 lớp Linear nữa, mỗi lớp Linear đại diện cho ma trận và . Lúc này nó giống như việc training một NN bình thường thôi. Chú ý là, hiện tại LoRA mới chỉ hỗ trợ phân tách weight của layer Linear, và chưa hỗ trợ cho những layer khác.
Ưu điểm của LoRA
Bên cạnh việc không có độ trễ inference như đã giải thích ở trên, hãy cùng xem xét thêm các ưu điểm của LoRA.
Đầu tiên là giảm số lượng tham số huấn luyện. Các tác giả của LoRA đã chứng minh được, so với GPT-3 175B được tinh chỉnh với Adam, LoRA có thể giảm số lượng tham số training 10.000 lần và giảm yêu cầu bộ nhớ GPU đi 3 lần. Một lợi thế liên quan là thiết kế cấp thấp của nó. Bởi vì nó chỉ tối ưu hóa các ma trận cấp thấp nên mang lại hiệu quả cho việc huấn luyện mô hình.
Ưu điểm tiếp theo là tính mô-đun. Bạn có thể xây dựng nhiều mô-đun LoRA nhỏ cho các nhiệm vụ khác nhau. Ưu điểm của tính mô-đun này tương tự như lợi thế của việc điều chỉnh tiền tố. Ví dụ: bạn có thể xây dựng mô-đun LoRA trên LLM cơ sở để tóm tắt văn bản và một mô-đun LoRA khác trên cùng LLM cơ sở cho câu hỏi và câu trả lời. Khi hai mô hình tinh chỉnh được triển khai để suy luận theo thời gian thực, bạn chỉ cần tải cùng một mô hình cơ sở một lần. Với kích thước vật lý của LLM ở mức hơn 100 GB, không thể bỏ qua lợi thế này.
Quá tình fine-tuning vẫn tiêu tốn nhiều GPU
Tuy chúng ta hài lòng với chiến lược không chạm tới hàng tỷ tham số trong mô hình được huấn luyện trước nhưng các thách thức vẫn chưa kết thúc. Việc tinh chỉnh LLM cũng cần nhiều GPU. Như một bài viết đã nói, chỉ để sử dụng (inference) mô hình BLOOM-176B sẽ yêu cầu GPU A100 8x 80GB. Nếu chúng ta muốn tinh chỉnh BLOOM-176B, chúng ta sẽ cần 72 GPU này. Các mô hình lớn hơn nhiều như PaLM thậm chí còn đòi hỏi nhiều tài nguyên hơn.
Có rất nhiều nỗ lực chung nhằm giảm việc sử dụng GPU trong suy luận và tinh chỉnh mô hình. Một bước phát triển quan trọng là int8 có thể giảm một nửa yêu cầu bộ nhớ mà không làm giảm hiệu năng của mô hình.
Các kĩ thuật đê giảm tài nguyên GPU
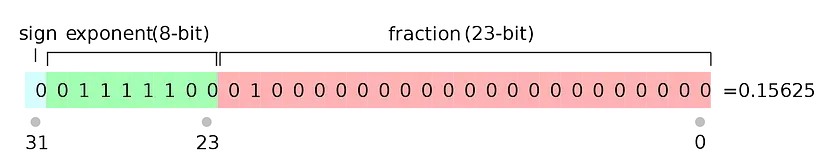
Chúng ta đều biết kích thước của một mô hình được xác định bởi số lượng tham số của nó, thực tế rằng độ chính xác của một tham số cũng quyết định rất lớn đến kích thước của mô hình. Một tham số thường được lưu trữ và trình bày trong float32. Float32 (FP32) là viết tắt của biểu diễn dấu phẩy động 32-bit IEEE được tiêu chuẩn hóa. Hình dưới biểu diễn dấu phẩy động 32 bit cho giá trị 0.15625. Biểu diễn 32 bit cho tất cả các tham số làm cho kích thước mô hình rất lớn.
Chúng ta có thể làm gì? Cộng đồng nghiên cứu đã đưa ra một định dạng mới, bfloat16 (BF16). Định dạng BF16 yêu cầu 2 byte so với định dạng FP32 yêu cầu 4 byte. Vì lý do này, định dạng FP32 được gọi là độ chính xác đầy đủ (4 byte) và định dạng BF16 có độ chính xác một nửa (2 byte).
Làm cách nào chúng ta có thể duy trì độ chính xác của các tham số và giảm yêu cầu về GPU? Chiến lược là áp dụng cách tiếp cận có độ chính xác hỗn hợp. Nó giữ các tham số của mô hình được huấn luyện trước trong FP32 làm trọng số chính trong khi thực hiện tính toán trong BP16. Trong quá trình tinh chỉnh, việc tính toán độ dốc được thực hiện trong FP16, sau đó được sử dụng để cập nhật các tham số chính.
Tuy nhiên, việc sử dụng BP16 với định dạng FP32 vẫn không làm giảm kích thước của mô hình xuống mức dễ quản lý hơn. Để khắc phục, Tim Dettmers và đồng bọn giới thiệu phương pháp lượng tử hóa 8 bit (int8 quantization). Bởi vì nó là 8 bit, tức 1/4 của 32 bit, nên nó có khả năng giảm kích thước của mô hình xuống còn 1/4. Rõ ràng, điều này không dễ dàng như vậy, nó sẽ gây ra sự xuống cấp của mô hình, việc dự đoán mô hình cũng sẽ bị ảnh hưởng. Biện pháp khắc phục là gì? Họ phát hiện ra rằng trong phép tính nhân ma trận, các giá trị outlier quan trọng hơn các giá trị non-outlier. Vì vậy, các giá trị outlier có thể được lưu trữ trong FP16 trong khi các giá trị non-outlier ở định dạng 8 bit hoặc được gọi là int8. Sau đó, các giá trị outlier và non-outlier được ghép với nhau để nhận kết quả đầy đủ trong FP16. Quá trình này đã được phát triển trong thư viện bitandbytes.
Đây là tiền đề cho việc sáng tạo ra phương pháp LoRA with Quantization (QLoRA), và chúng ta sẽ thảo luận kĩ hơn về nó ở bài viết sau, cùng với LongLoRA nhé. Chào thân ái và quyết thắng!
Tham khảo
LoRA: Low-Rank Adaptation of Large Language Models
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale