- Published on
Từ LoRA đến LongLoRA: Nhẹ hơn, dài hơn và sướng hơn - Phần 2
- Authors

💡 Mọi người có thể đọc bài viết phần 1 của mình về LoRA tại đây để hiểu rõ hơn trước khi đọc bài viết này nha.
Chúng ta đều biết LoRA được sử dụng như một phương pháp tối ưu việc fine-tuning mô hình bằng cách đóng băng toàn bộ tham số và chỉ huấn luyện trên một phần nhỏ (cỡ 15 - 20%) của toàn bộ model để có thể huấn luyện trên các máy tính có cấu hình hạn chế. Vậy thì, QLoRA là gì, LongLoRA là gì và tại sao lại cần đến hai kĩ thuật này?
QLoRA là gì?
Để hiểu đơn giản, QLoRA = Quantization + LoRA, mà kĩ thuật quantization (lượng tử hóa) mình đã giới thiệu ở phần 1 của bài viết này rồi. Với sự có mặt của QLoRA, mình đã có thể fine-tune mô hình 7 tỷ, 13 tỷ và 33 tỷ tham số với 2 con RTX 3090. Đáng nói là mô hình 7 tỷ tham số chỉ chiếm 4-5GB/GPU, tức là ~10GB, hoàn toàn có thể training trên Google Colab.
Cách lượng tử hóa trong QLoRA
Sau khi xác định được kiểu dữ liệu (dtype) cần sử dụng, bước tiếp theo là áp dụng công thức để chuyển đổi từ dtype gốc (source dtype) sang dtype mà chúng ta muốn quantize (target dtype). Để đảm bảo rằng chúng ta có thể sử dụng toàn bộ giá trị của target dtype, chúng ta sẽ tỉ lệ hóa source dtype về khoảng target dtype bằng cách chuẩn hóa với giá trị tuyệt đối lớn nhất hiện có của source dtype. Ví dụ, quá trình quantize từ FP32 về INT8 với khoảng giá trị là sẽ được thực hiện như sau:
với là hằng số quantize, là phép làm tròn.
Ví dụ, ta có tensor ở dạng FP32 muốn quantize về INT8, thì hằng số quantize và tensor mới ở dạng INT8 là .
Để đảo ngược từ target dtype về source dtype, ta có quá trình de-quantize:
QLoRA đã làm gì để đạt được hiệu quả đó?
QLoRA: Quantized LoRA là một paper về quantization kết hợp vs LoRA để giúp training các mô hình siêu nặng một cách dễ dàng. QLoRA giới thiệu ba điểm mới:
- NF4 (Normal Float 4): Một dtype mới, sử dụng chỉ 4 bit nhưng độ chính xác lại ở mức cực tốt
- Double Quantization: Quantize 2 lần
- Paged Optimizers: Tránh lỗi OOM
Chúng ta sẽ cùng nhau đi tìm hiểu các ba điểm mới ở trên, nhưng trước hết, hãy lưu ý rằng: QLoRA quantize tham số về NF4, nhưng sau đó phải dequantize lên BF16 để tính toán bởi vì hiện tại các GPU chưa hỗ trợ việc tính toán bằng dtype NF4.
NF4 là gì, có ăn được không?
QLoRA sử dụng kĩ thuật quantize gọi là Quantile Quantization. Thay vì chia khoảng giá trị thành từng đoạn bằng nhau như ở Quantize thông thường, thì Quantile Quantization sẽ coi khoảng giá trị như một cái phân phối, và chia làm sao cho từng phần trong phân phối đấy có xác suất xảy ra bằng nhau. Một khoảng được chia như dưới kia sẽ gọi là một quantile.
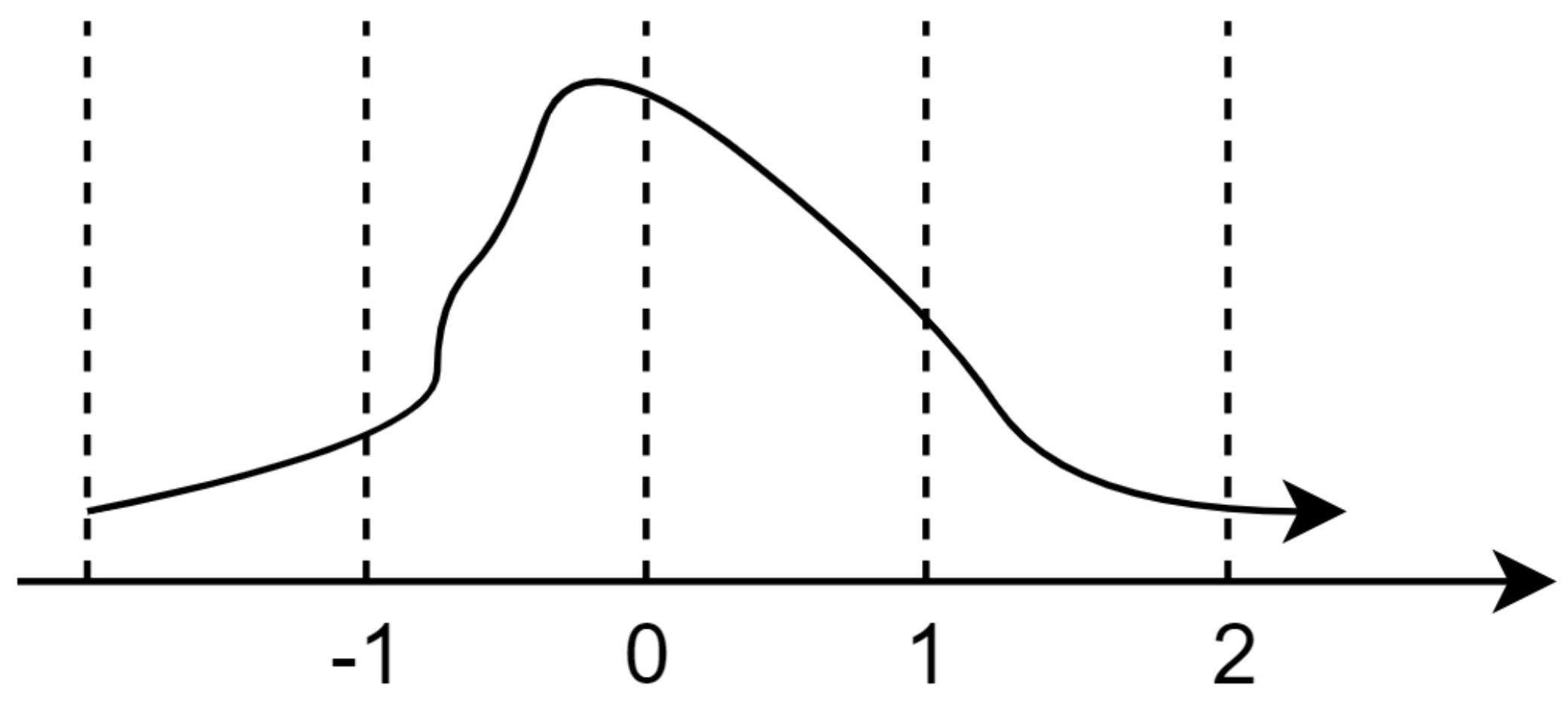
Trong một tensor, có thể xảy ra hiện tượng outlier, tức là có một số giá trị xuất hiện rất hiếm, nhưng lại có giá trị rất lớn hoặc rất nhỏ so với các giá trị còn lại trong tensor. Những giá trị này thường mang tính quan trọng đặc biệt và cần phải được biểu diễn chính xác. Tính chất của Quantile Quantize là các khoảng quantile phải có xác suất bằng nhau, dẫn đến việc các giá trị outlier như 2.75 sẽ được gộp vào các khoảng từ 1.5 trở đi. Để khắc phục vấn đề này, thay vì quantize cả tensor (bao gồm nhiều phần tử) một cách toàn diện, chúng ta sẽ chia tensor thành nhiều phần nhỏ hơn (chunks) và quantize mỗi chunk của tensor đó riêng biệt.
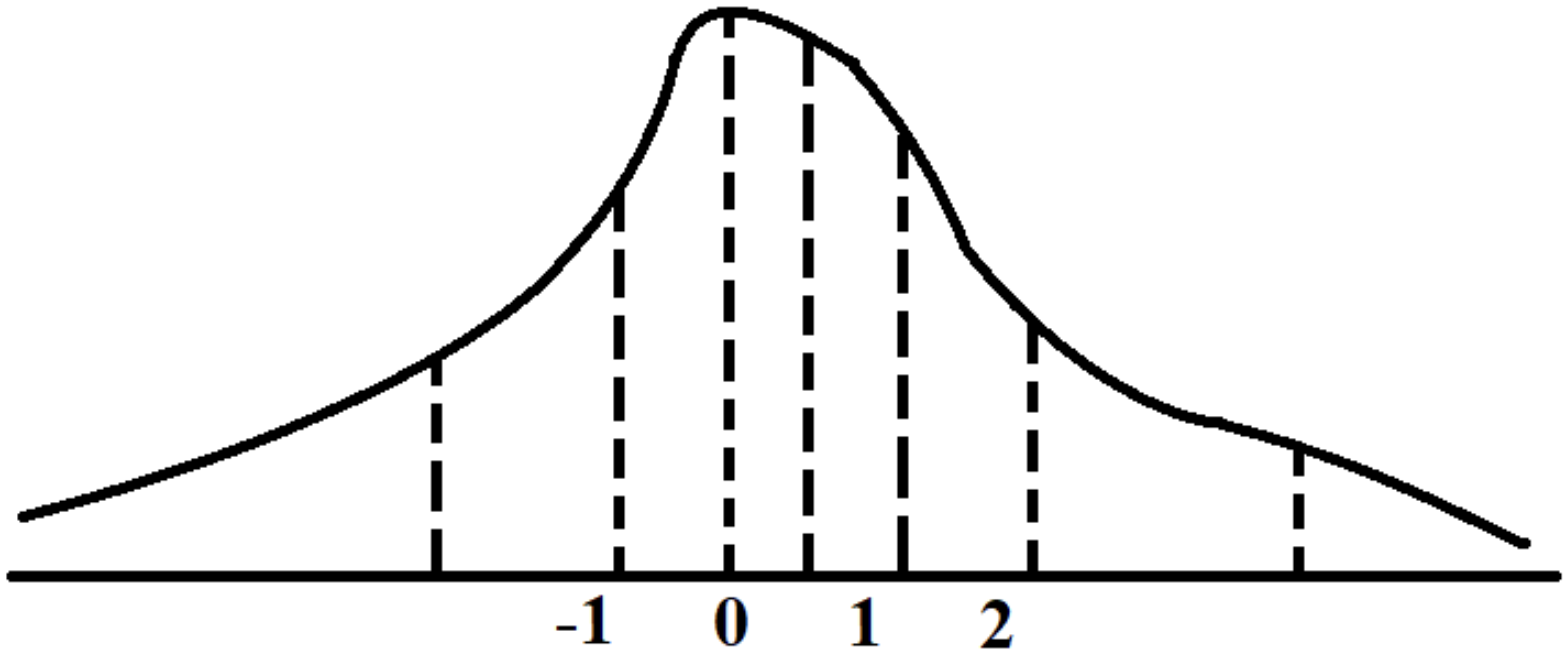
QLoRA áp dụng kỹ thuật Quantile Quantization trong quá trình huấn luyện. Tuy nhiên, việc xác định quantile phù hợp cho từng tensor weight đòi hỏi nhiều thời gian vì tính khó khăn trong quá trình này. Mặc dù có các thuật toán xấp xỉ quantile nhanh, nhưng chúng không phản ánh tốt sự xuất hiện của outlier. Để giải quyết vấn đề này, QLoRA đã nhận ra rằng nếu tất cả các tensor tuân theo cùng một loại phân phối cố định, chúng ta chỉ cần xác định các quantiles một lần duy nhất và áp dụng chúng cho toàn bộ các tensor weight thay vì phải tìm quantiles phù hợp cho từng tensor riêng lẻ. QLoRA đã tiến hành các thí nghiệm để chứng minh rằng đa số các tensor weights của pre-trained LLM tuân theo phân phối chuẩn với mean 0 và standard deviation . Do đó, QLoRA đã điều chỉnh toàn bộ các weights về một phân phối cố định bằng cách chia cho , đảm bảo rằng phân phối sẽ nằm trong khoảng giá trị của target dtype.
QLoRA muốn quantize weights của mạng nơ-ron về một khoảng giá trị cụ thể là cho target dtype. Tuy nhiên, việc sử dụng các phương pháp quantile thông thường sẽ không thể biểu diễn chính xác số 0 (vị trí trung tâm, Q2). Để giải quyết vấn đề này, số quantiles được chia thành hai phần: cho phần âm kèm số 0 và cho phần dương kèm số 0. Sau đó, hai phần này được kết hợp lại và một số 0 được loại bỏ (do số 0 được tính hai lần). Đây là cách NF4 được tạo ra.
Túm cái váy lại, NF4 có các đặc điểm sau:
- Sử dụng 4 bits biểu diễn.
- Nằm trong khoảng .
- Bất đối xứng, có sự biểu diễn cho giá trị 0.
- Được tạo ra để áp dụng cho tensor tuân theo phân phối chuẩn mean 0 và std 1.
Để thực hiện quantize tensor weight về NF4, trước tiên ta phải scale tensor weight về khoảng , sau đó ta thực hiện quantize như bình thường. Lưu ý, bước này sẽ bao gồm áp dụng cả Chunk Quantize.
Double Quantization
Double Quantization, như tên gọi của nó, thực hiện quá trình quantize hai lần. Khi thực hiện Chunk Quantize và sử dụng nhiều chunks, mỗi chunk sẽ có một hằng số quantization riêng của nó. Việc này dẫn đến tăng bộ nhớ cần thiết để lưu trữ các hằng số quantization. Do đó, QLoRA thực hiện quá trình quantize cho cả các hằng số quantization từ FP32 sang FP8.
Paged Optimizers
Khi huấn luyện mô hình trên GPU, việc gặp lỗi "Out of Memory" (OOM) là phổ biến. Paged Optimizers giúp giải quyết vấn đề này bằng cách sử dụng Unified Memory trên GPU Nvidia. Khi xảy ra lỗi OOM, các dữ liệu và tài nguyên khiến cho GPU bị OOM sẽ được chuyển tạm thời sang CPU, tức là chuyển dữ liệu từ bộ nhớ VRAM sang RAM. Khi GPU cần lại các tài nguyên này để tính toán, chúng sẽ được đòi lại từ CPU. Điều này giúp tránh lỗi OOM và tiếp tục quá trình huấn luyện mô hình một cách hiệu quả trên GPU.
Cơ chế hoạt động
QLoRA hiện tại chỉ hỗ trợ cho Linear layer (vì LoRA cũng chỉ hỗ trợ cho Linear). Một layer sẽ gồm 2 thành phần: Thành phần pretrained (freeze) và thành phần LoRA (train). Quá trình tính toán output của layer Linear có LoRA đó như sau:
với như sau:
Trong một Linear layer có LoRA, thành phần được pretrained được đóng băng và không cập nhật gradient, trong khi thành phần LoRA được huấn luyện. Trọng số của thành phần pretrained được quantize về NF4. Trong quá trình tính toán output, thành phần pretrained được dequantize từ NF4 về BF16, sau đó được kết hợp với thành phần LoRA ở dạng BF16. Khi tính toán hoàn tất, thành phần pretrained lại được quantize về NF4. Nhờ vậy, QLoRA giúp model vừa với VRAM để huấn luyện, mặc dù không tăng tốc độ của model (do cần dequantize thành phần cần tính toán về BF16 tại mỗi layer).
LongLoRA là gì?
Chúng ta đã xong phần nhẹ hơn rồi, vậy thì dài hơn ở đâu mà sướng, và đây, đúng như tên gọi của nó, LongLoRA là kĩ thuật để kéo dài context văn bản được sử dụng để mở rộng khả năng học của mô hình. Chẳng hạn, với Llama-2 7B, độ dài context là 4096 tokens, đồng nghĩa với việc nó chỉ có thể mã hóa được đoạn văn bản với 4096 từ. Điều này gây ra sự khó khăn cho những mô hình chuyên dụng để truy xuất thông tin từ sách, báo. Do đó, Yukang Chen cùng đồng bọn đã nghiên cứu và đề xuất LongLoRA, với khả năng mở rộng context lên đến 100,000 tokens. Điều này có thể cho phép bạn tóm tắt kịch bản phim Cô dâu 8 tuổi trong vòng 50 từ :D.
Cơ chế của LongLoRA
Nói ngắn gọn rằng, LongLoRA đạt được chiều dài context đáng kể bằng cách thay đổi hai yếu tố sau:
- Shifted Sparse Attention (S2-Attn): Nhóm tác giả đề xuất S2-Attn thay thế cho cơ chế multihead self-attention có sẵn trong Transformer để tăng tốc độ và giảm chi phí tính toán.
- LongLoRA cho phép hai tham số embedding và normalization thay đổi dựa trên dữ liệu đưa vào (trainable). Điều này có vai trò then chốt đối với việc mở rộng context và chỉ giới thiệu một số lượng tối thiểu các tham số có thể training.
Phần còn lại, LongLoRA làm hoàn toàn giống hệt LoRA và không có quá nhiều sự khác biệt nào đáng kể. Vậy mới thấy, việc đem 2 tham số embedding và normalization ra để training có sức ảnh hưởng lớn tới performance của mô hình.
Shifted Sparse Attention (S2-Attn)
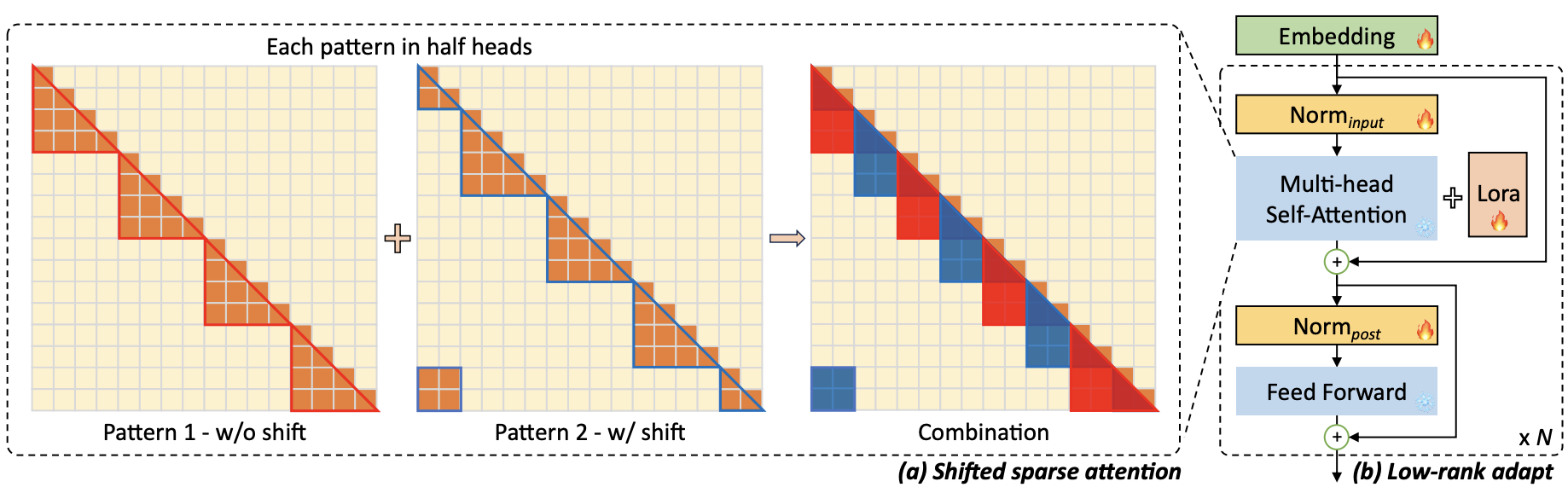
Nhóm tác giả đề xuất S2-Attn bằng cách dịch chuyển các partition với khoảng dịch chuyển bằng một nửa group size của attention head. Ví dụ, xét context length 8192 ở hình trên, trong Pattern 1, nhóm đầu tiên tiến hành self attention từ token 1 đến 2048. Trong Pattern 2, group partition được dịch chuyển 1024. Nhóm tiên bắt đầu từ 1025 và kết thúc ở token thứ 3072, trong khi 1024 token đầu tiên và cuối cùng thuộc cùng một nhóm. S2-Attn được áp dụng bằng việc ghép cả 2 pattern 1 và 2 lại với nhau, tương ứng ở mỗi nửa self-attention head. Cách này không làm tăng chi phí tính toán bổ sung nhưng cho phép luồng thông tin giữa các nhóm khác nhau.
Nghe thì có vẻ phức tạp đúng không, nhưng thực ra, S2-Attn hoàn toàn dễ dàng để áp dụng, với 2 bước cơ bản:
- Dịch chuyển token trong self-attention head,
- Chuyển các feature từ token dimension sang batch dimension.
Repository tham khảo
Nhóm tác giả đã cung cấp repository của LongLoRA ở đường link này. Các bạn có thể tìm hiểu đọc và thực hiện với các mô hình có sẵn.
Tham khảo
LoRA: Low-Rank Adaptation of Large Language Models
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
Đôi lời cuối năm
Hôm nay cũng là 29 Tết rồi, có lẽ mọi người cũng đã gói bánh xong, Tất niên xong hoặc chuẩn bị Tất niên, nhưng mọi người đã dành thời gian ở đây, để đọc bài viết này cho đến tận dòng cuối cùng. Minh cảm ơn tất cả mọi người đã quan tâm đến blog của mình và và chúc cho các bạn và gia đình một năm mới hạnh phúc, bình an, và nhiều thành công hơn nữa.
Happy new year!